Quintessence
Project Overview
Quintessence seeks to add state-of-the-art data analysis and dynamic corpus exploration to the study of Early Modern period English texts. This project currently uses a corpus of approximately sixty thousand texts from the Early English Books Online (EEBO) Text Creation Partnership. Each text is standardized using Northwestern University’s MorphAdorner, which accounts for spelling changes over time. Any scholar interested in the archive can use Quintessence to run analyses ranging from individual word meanings to broad textual themes. The ability to add more collections of texts is under active development.
The namesake quintessence comes from our tool’s ability to show conceptual similarity between seemingly disparate ideas and authors. This vignette details how John Wilkins and George Herbert, two thinkers who outwardly have very different focus and perspectives, write about very similar concepts in their meaning of quintessence. Where John Wilkins was the embodiment of the plain-speaking rational man, George Herbert was a “metaphysical poet” par excellence. Nevertheless, both concern themselves with the study of existential topics and religion, emphasizing both mind and body, man and nature. This connection is obscured if only the word choices of these authors are compared, yet clear if the conceptual topics they discussed are observed instead.
Words Meanings Over Time
The meaning of individual words can evolve over time. We use word embeddings to follow this evolution and to track the meaning of specific terms in relation to others in the corpus. The Word Meanings tool of quintessence allows you to search for any term in the corpus, and see a plot of that word’s change. You can hover on the word at each decade to see its overall Similarity Score, as well as the other nearest terms in that decade. The word is also shown in context below the graphs.
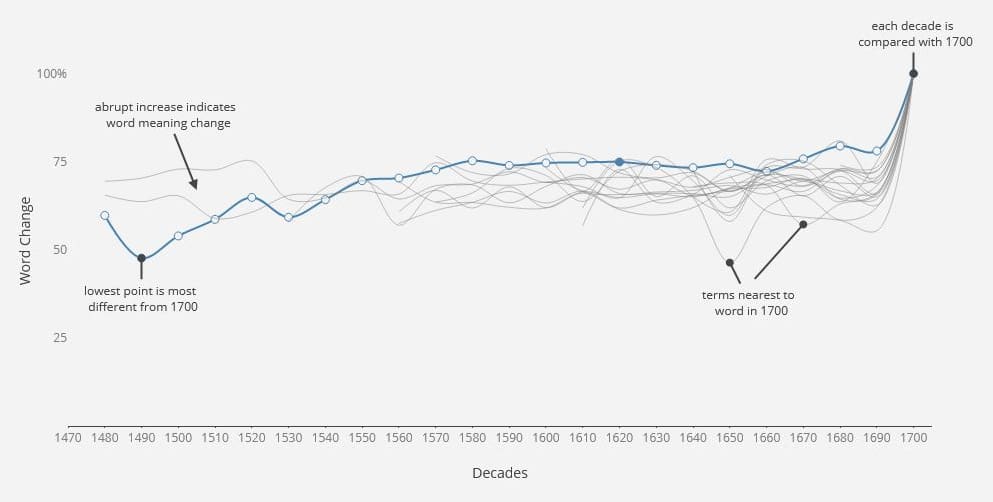
Word embeddings are numerical representations of a word, generated by examining each word in the context of all other words in a corpus. This comparison allows words to be “mapped” as a point in a cloud of other words, with words clustered together in this could having similar meaning. By creating several of these clouds over time, we can see how individual words move in this “meaning space” and change over time.
Word meanings can also change with location, as local dialects change and adapt. Using the Most Similar Words (Location) tool, you can enter a term and find the most similar words by geographical location. These locations were created for each work by looking at the front matter included in each work, and adding the printing location as metadata to the work. There is similar functionality for finding word meaning by author, where the corpus is filtered to contain only works by prominent writers.
Text Topics
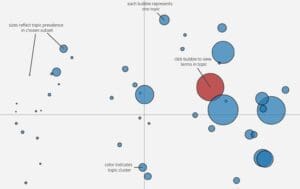
Quintessence includes a corpus wide topic model that identifies common themes across texts by grouping words according to their co-occurrence with other words. If words co-occur in some texts and not others, the model will associate those words and documents with a common topic.
Dozens of topics were generated across the Quintessence corpus covering ideas such as religion, commerce, and metaphysics. By comparing texts which have similar topic prevelances, you can see what ideas are being discussed regardless of author, diction, or time period.
Word Frequency
Quintessence provides several tools to graph word occurrence over time within the corpus. The frequency over time plot allows you to graph the prevalence of up to five words in the corpus by year and compare their prevalence; words per decade provides similar functionality with bar plots. The documents per decade plot instead shows how many documents per decade contain the words of interest provided.
Upcoming
The team behind Quintessence is working to expand the capabilities of the tool. Current work is focused on making the site more stable, responsive, and robust. These improvements will lay the groundwork for several exciting new features, the most exciting of which is the ability to seamlessly integrate new bodies of text into the site.
Future improvements will focus on making individual documents the focus of analysis. With our upcoming document view, users will be able to read individual documents in the corpus, and see how words on the page relate to the corpus as a whole. By highlighting a term of interest, users will be able to track meaning shifts over time, see word topic importance, as well as how it relates to other words and documents in the corpus overall.
To test out the Quintessence tool for yourself, visit the site here.
DataLab Contact
- Carl Stahmer and Arthur Koehl (technical leads)