Creating Co-Author Networks in R
Project Overview
A tutorial by DataLab postdoctoral Scholar, Jane Carlen
A co-author network is a great way to get a snapshot view of the breadth and depth of an individual’s body of research. I created such graphs and corresponding visualizations to highlight and celebrate the work of UC Davis scholars.
In this post I will describe the packages I used to do this, common roadblocks and ways around them. I will highlight the use of interactive and dynamic co-author networks, which are especially useful for visualizing large co-author networks. I will assume some familiarity with R, and experience working with data structures likes lists and vectors, but no prior familiarity with packages for working with networks.
As an example, I will use the work of Louise H. Kellogg, a professor in the Department of Earth and Planetary Sciences at UC Davis who passed away in 2019. I created visualizations of her author network as a way of showcasing and honoring her contribution to her field.
Packages
Citation and network packages to load
library(scholar)
library(networkDynamic)
library(ndtv)
library(igraph)
library(statnet)
library(intergraph)
library(visNetwork)Helper packages
library(dplyr)
library(stringr)The Data
In an ideal world you begin this process with a perfectly cleaned and standardized data set. In this perfect world no two authors have the same name, every author goes by only one set of initials (i.e. Jane Carlen wouldn’t be listed as J. Carlen and J. A. Carlen), and every paper includes all relevant fields (title, author, year, etc.). Sadly, this is almost never the case. Like most data science projects, the majority of your time will be spent cleaning and standardizing your data. The exact steps to scrub the data are specific to each project and usually fairly straightforward (involving a lot of author name googling), so I will focus on only generally relevant cleaning tasks.
Two Starting Points
1. You have no data.
In this case, a convenient starting point is the scholar package (https://cran.r-project.org/web/packages/scholar/index.html).
To begin to craft Louise Kellogg’s co-author network, I looked for her google scholar page. Not all authors have them, but it’s a good starting point for those who do. If present, the scholar’s ID is there in the url. Louise Kellogg’s is “NP_WECMAAAAJ”. Then I use the get_publications function from scholar. There are function arguments to control how many publications it pulls, but I’ve found them to have unexpected behavior.
kellogg = get_publications("NP_WECMAAAAJ") #id from url in google scholar page
#convert factor variables to strings
kellogg[,sapply(kellogg, class)=="factor"] =
as.character(kellogg[,sapply(kellogg, class)=="factor"])
saveRDS(object = kellogg, "kellogg_scholar_pull.RDS")
> names(kellogg)
[1] "title" "author" "journal" "number" "cites" "year"
[7] "cid" "pubid" There is a strict limit on the number of time you can query google scholar in a day, so I recommend saving the output of get_publications as soon as you pull it so you don’t have to re-run the query.
A major limitation of a pull from google scholar is that the number of authors is capped at 5, and if a paper has more authors than that they will be obscured under an “…” entry in the author field of the output.
You can deal with this by using the get_complete_authors function in the scholar package, but this also runs up against the query limit fairly quickly. I make sure to restrict those queries to only the publications with an “…” in the author name. Again, I save the output as soon as I get it so that I only need to run the query once. Here is an example:
ellipsis_indices = grep(kellogg$author, pattern = "\\.\\.\\.")
author_complete = sapply(kellogg$pubid[ellipsis_indices],
get_complete_authors, id = "NP_WECMAAAAJ")
saveRDS(object = author_complete, file = "author_complete.RDS")author_complete, the output from get_complete_authors, needs to be reformatted if it is to be inserted into the author field of the data frame kellogg (the output from get_publications). Each element in the list author_complete is a single string of authors names separated by commas. First names in this string are not abbreviated. In contrast, names in kellogg$author are formatted with first and middle names abbreviated, e.g. “JA Carlen”. It is also possible for the author names in author_complete to have special characters. I wrote the following code to handle all this reformatting:
First, a couple one-line helper functions to reformat names:
#helper function to put last names in a regular format (first letter uppercase, rest lowercase):
lowerName <- function(x) {gsub(x, pattern = "\ ([A-Z]){1}([A-Z]+)", replacement = '\ \\1\\L\\2', perl = TRUE)}
#helper function to convert a name to an initial (applied after lowername):
initialName <- function(x) {gsub(x, pattern = "([A-Za-z]){1}([a-z]+)", replacement = '\\1', perl = TRUE)}Then I can standardize name formatting into INITIALS, Lastname (e.g. JA Carlen):
author_complete_reformat = lapply(author_complete, function(elem) {
# Split strings of authors into individual authors based on commas:
split_elem = strsplit(elem, ", ")[[1]]
split_elem = sapply(split_elem, gsub, pattern = "(\\x.{2})+", replacement ="")
# Put author names into INITIALS, Lastname format:
rename_elem = sapply(split_elem, function(name) {
#in case of name like "H J\xfc\xbe\x8d\x86\x94\xbcrvinen":
name2 = iconv(name, "latin1", "ASCII", sub = "")
name2 = lowerName(name2)
name2 = strsplit(name2, " ")[[1]]
lastname = last(name2)
if (length(name2) > 1) {
name2 = sapply(1:(length(name2)-1), function(i) {initialName(lowerName(name2[i]))})
name2 = paste(paste(name2, collapse = ""), lastname, sep = " ")
} else {
name2 = lastname
}
return(name2)
})
# Put separated names back in single strings:
rename_elem = paste(rename_elem, collapse = ", ")
return(rename_elem)
})Once the names have been reformatted I can slot them back in the kellogg data frame:
# Save original author column as "author_orig" and update the "author column"
kellogg$author_orig = kellogg$author
kellogg$author = as.character(kellogg$author)
kellogg$author[ellipsis_indices] = author_complete_reformatFilling in authors that had been truncated to “…” is especially important when creating co-author networks because otherwise many co-authorship relationships would be missed.
One more cleaning step that I will touch on is unifying the spelling of author names. Although I have reformatted names, it’s possible that I have entries like “L Kellogg” and “LH Kellogg” that refer to the same person. The following line of code will correct this for me, turning all instances of “L Kellogg” into “LH Kellogg”. (I just need to be careful when joining names that I’m not mistakenly condensing distinct authors whose names only differ by an initial.) Note I’m using the str_replace function from the R package stringr which helps to make string manipulation code like this very readable.
kellogg$author = sapply(kellogg$author, str_replace, pattern = "L Kellogg", replacement = "LH Kellogg")*Note: In writing this post, I found a helper package to turn google scholar pulls into networks in a couple easy steps: https://github.com/pablobarbera/scholarnetwork/tree/master/R. If this suits your needs it’s a very easy way to get from A to Z, but it bypasses quality-control steps like cleaning author names and filling in authors truncated to “…”. *
At this point, I’m in the scenario of our second starting point, so I’ll shift to that now.
2. You have an existing data set with fields like author, year, title and journal.
Let’s assume I have a data frame of publication information that resembles our reformatted kellogg data frame. I won’t dwell on additional cleaning steps like removing duplicate publications, though more cleaning may be necessary.
Creating Nodes, Edges and the Network for a Co-Author Network
I will demonstrate the next steps of co-author network visualization under the assumption that the data is clean. My demonstrations will use a version of the kellogg data that was thoroughly cleaned. Click this link to download the cleaned data and follow along. Then load with the following line. (Note that the path to your downloaded cleaned data set may need to adjusted for your system.)
kellogg = read.csv("~/Downloads/Kellogg_cleaned.csv", stringsAsFactors = FALSE)In my co-author network the nodes (also called vertices) represent authors and the edges between them represent co-authorships. I need to split strings containing multiple authors for each publication into individual entries as a first step in creating a set of nodes.
Nodes (Authors)
The following code creates a list equal in length to the number of publications, where each entry is a vector of length equal to the number of authors on a given publication.
kellogg.coauthors = sapply(as.character(kellogg$author), strsplit, ", ")It’s a good precautionary measure to clean whitespace from all individual names:
kellogg.coauthors = lapply(kellogg.coauthors, trimws)I create the node set (alphabetized):
kellogg.coauthors.unique = unique(unlist(kellogg.coauthors))[order(unique(unlist(kellogg.coauthors)))]Edges (Co-Authorships)
I start to create the edge set by tracking which authors appear in which papers. These can be referred to as bipartite edges because entities (authors and papers) are only connected to entities of a different class. (Authors are connected to papers and vice versa.)
kellogg.bipartite.edges = lapply(kellogg.coauthors, function(x) {kellogg.coauthors.unique %in% x})
kellogg.bipartite.edges = do.call("cbind", kellogg.bipartite.edges) # dimension is number of authors x number of papers
rownames(kellogg.bipartite.edges) = kellogg.coauthors.uniquekellogg.bipartite.edges is a matrix of dimension equal to the number of papers by the number of unique authors in our data set. I can project the bipartiate edges (between authors and papers) into unimode edges (between authors) using matrix multiplication (%*%).
kellogg.mat = kellogg.bipartite.edges %*% t(kellogg.bipartite.edges) #bipartite to unimode
mat = kellogg.mat[order(rownames(kellogg.mat)), order(rownames(kellogg.mat))]Network
One way to create a network from kellogg.mat where edge values correspond to the number of co-authorships between authors is to use the statnet package. Specifically, this is done by using the as.network function, setting ignore.eval to FALSE, and storing the edge weight attribute as edge.lwd using the names.eval argument. This works because the values in the matrix kellogg.mat represent numbers of co-authorships between authors. I set directed to FALSE because co-authorship relationships are undirected.
kellogg.statnet = as.network(kellogg.mat, directed = FALSE, names.eval = "edge.lwd", ignore.eval = FALSE)
kellogg.statnet # view network summaryNote that a vertex attribute vertex.names is automatically added to the network, kellogg.statnet. It contains the author name associated with each node, and it was automatically extracted from the row names of kellogg.mat.
Then I’m ready to make a first iteration of the co-author network plot.
Static Visualization
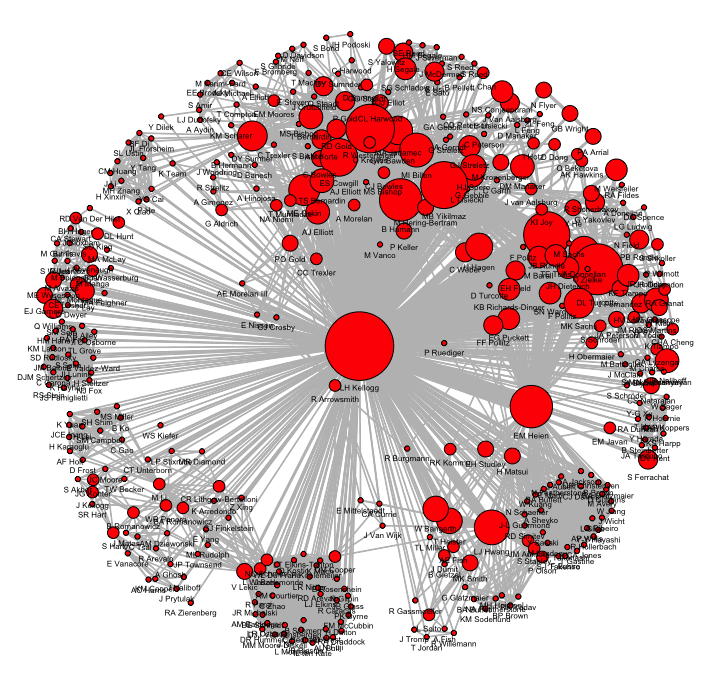
I can further customize the plot by adding more attributes to the nodes and/or edges in the graph, and then incorporating them in the plot. This is done using the %e% and %v% syntax of statnet. For example, I can base the size of nodes in the plot on the degree of each node in the network. The degree of each node (author) in this network is the same as their number of co-authorships with Louise Kellogg, since she is an author of every paper in the data. I may also want to log-transform these degrees to make the scale more appropriate for visualization.
author.codegree = kellogg.mat["LH Kellogg",]
kellogg.statnet%v%"size" = log(author.codegree) + .5 #plot.network(kellogg.statnet, edge.col = “gray”, edge.lwd = kellogg.statnet%e%”edge.lwd”,
label = “vertex.names”, label.cex = .5, label.pad = 0, label.pos = 1, vertex.cex = “size”)I can see that the value of a static plot is limited by the overplotting of name labels. It is difficult to see how specific authors are connected. I can improve on this by switching to an interactive plot.
Interactive Visualization
One way to create an interactive network plot is to use the visNetwork package. The most basic way to create a plot using this package is to first build data frames describing the nodes and edges in the graph.
kellogg.nodes <- data.frame(id = 1:length(kellogg.statnet%v%"vertex.names"),
label = kellogg.statnet%v%"vertex.names",
title = kellogg.statnet%v%"vertex.names",
size = 5*(2+kellogg.statnet%v%"size"))
kellogg.edges <- data.frame(from=data.frame(as.edgelist(kellogg.statnet))$X1,
to=data.frame(as.edgelist(kellogg.net))$X2)I feed these into the visNetwork function, and I can control the size and layout of the output using this and visIgraphLayout. Note that the fields “label”, “title” and “value” in kellog.nodes have special meaning to visNetwork. For example, the title field is automatically used for the hovertext, and the size field determines the node size. label is used to identify authors in the dropdown menu we’ll add below.
kellogg_interactive = visNetwork(kellogg.nodes, kellogg.edges, main = "Louise Kellogg's Co-Author Network", width = 800, height = 800) %>%
visIgraphLayout(layout = "layout_nicely", type = "full")I can precisely customize how nodes and edges appear. For example, the following code highlights nodes red when clicked, and thickens highlighted edges in blue. When a node is selected, it’s connected edges are highlighted. Experiment with clicking and dragging nodes.
kellogg_interactive = kellogg_interactive %>%
visNodes(color = list(background = "white", highlight = "red", hover = list(border = "red"))) %>%
visEdges(selectionWidth = 10, color = list(highlight = "#2B7CE9"))
kellogg_interactive # view interactive networkWe can add a dropdown menu that allows us to select an author to highlight from a list.
kellogg_interactive = kellogg_interactive %>%
visOptions(nodesIdSelection = list(enabled = TRUE, useLabels = TRUE, main = "Select by Author"))The final output can be saved using the visSave command. I recommend reading the documentation for visNodes, visEdges, and visOptions to see more customization options. Be warned though that the options don’t always work quite as you would expect based on documentation, and can interact in unexpected ways. I usually get almost all of the features I want in a plot to appear, but often have to give up on one or two.
Click here to see an example of this interactive visualization.
visSave(kellogg_interactive, "Kellogg_coauthor_network.html", selfcontained = T)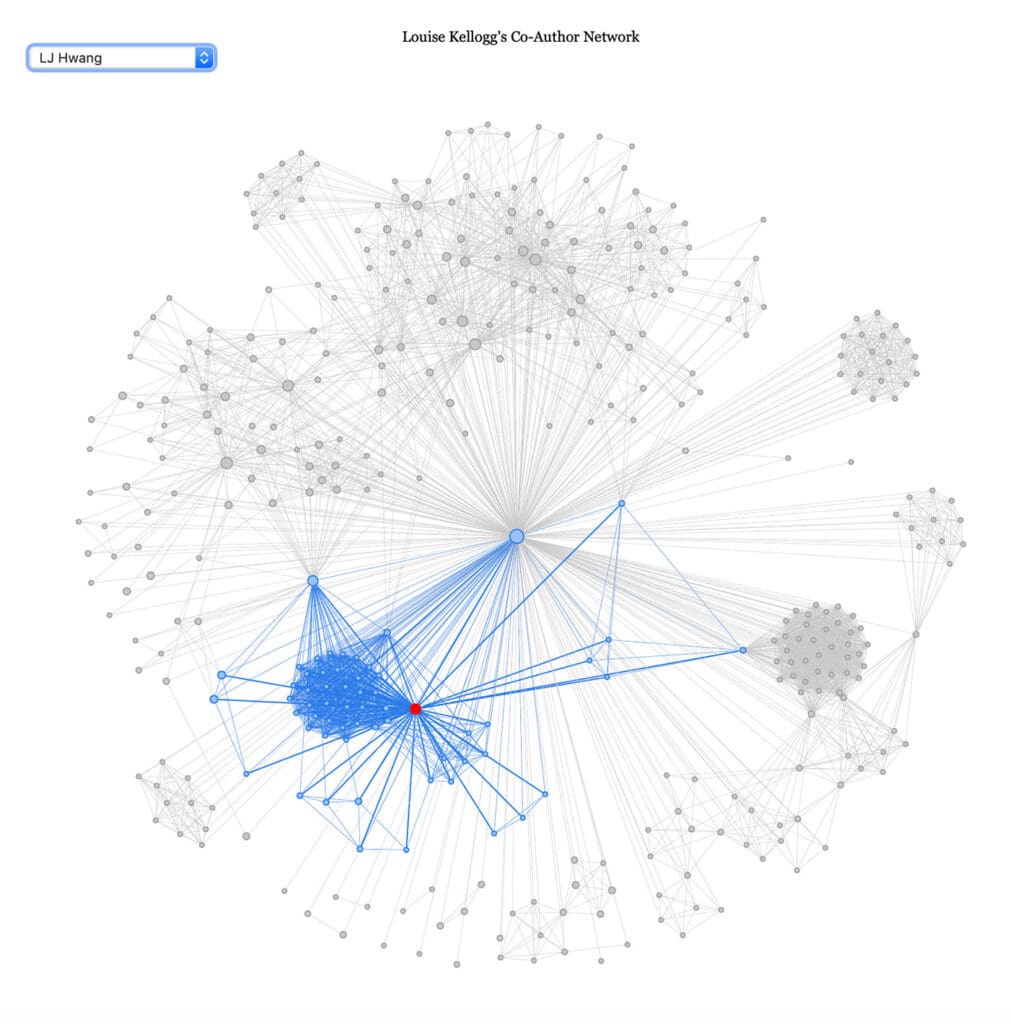
A note about IGRAPH
statnet is just one R package available for creating and plotting networks.
I could also have used igraph, or I could have converted from a statnet network to an igraph network using the intergraph package.
kellogg.igraph = intergraph::asIgraph(kellogg.statnet)I can feed an igraph network directly into an in interactive plot using visIgraph from the visNetwork package, e.g. visIgraph(kellogg.igraph), and I can layer in more customization as desired.
Dynamic Visualization (Over Time)
Finally, we can use the data set to create a dynamic visualization that shows how Louise Kellogg’s co-author network grew throughout her academic career. We use the year variable of kellogg to create a list of sub-networks of all connections up to a given year.
kellogg$year = as.numeric(kellogg$year)
table(kellogg$year)
slices = seq(min(kellogg$year), max(kellogg$year), by = 1)
start1= min(slices); end1 = max(slices)
author.first = sapply(kellogg.coauthors.unique,
function(x) {
min(kellogg[which(sapply(kellogg.coauthors, function(y) {x %in% y})),"year"], na.rm = T)
})
kellogg.network.list = lapply(slices, function(i) {
authors.sub = author.first <= i
kellogg.sort = subset(kellogg, kellogg$year <= i)
N.sub = sum(authors.sub)
P.sub = nrow(kellogg.sort)
kellogg.edges.sub = lapply(kellogg.edges[kellogg$year <= i], function(x) x[authors.sub])
tmp = matrix(do.call(cbind, kellogg.edges.sub), nrow = N.sub, ncol = P.sub)
rownames(tmp) = kellogg.coauthors.unique[authors.sub]
coauthor.mat = tmp %*% t(tmp)
coauthor.net = as.network(coauthor.mat, directed = F, names.eval = "edge.lwd", ignore.eval = F)
coauthor.net%v%"author" = kellogg.coauthors.unique[authors.sub]
coauthor.net%v%"x" = kellogg.layout$x[authors.sub]
coauthor.net%v%"y" = kellogg.layout$y[authors.sub]
coauthor.net%v%"vertex.pid" = which(authors.sub)
coauthor.net%v%"vertex.cex" = author.codegree[authors.sub]
return(coauthor.net)
})I used a workaround of empty networks to set the indexing in the animation to start at the first year in the data.
tmp = vector(mode = "list", length=min(slices)-1)
tmp = lapply(tmp, function(x) kellogg.network.list[[1]])
kellogg.network.list = c(tmp, kellogg.network.list)One package to create a dynamic visualization which is compatible with statnet and simple to use is networkDynamic. However, customization is limited in the resulting appearance. If you are looking for high-level customization you may look into using gganimate with ggraph, as in this gganimate example on Twitter.
kellogg.dynamic = networkDynamic(base.net=kellogg.statnet,
network.list = kellogg.network.list,
vertex.pid = "vertex.pid", create.TEAs = T)
kellogg.dynamic
compute.animation(kellogg.dynamic, animation.mode = "useAttribute",
slice.par=list(start=start1, end=end1, interval=1, aggregate.dur = 1, rule='latest'),
weight.attr = c("edge.lwd"))
render.d3movie(kellogg.dynamic, usearrows = F, displaylabels = T,
label= "author",
vertex.cex = "vertex.cex",
vertex.tooltip=paste(kellogg.statnet%v%'author', sep = "<br>"),
label.col = "white",
label.cex = .8,
vertex.col = "skyblue4",
edge.col = "navy",
edge.lwd = "edge.lwd",
main = "Louise Kellogg Co-Author Network over Time: 1986 - 2019",
xlab = "test",
bg="black",
vertex.border="#333333",
render.par = list(show.time = TRUE, show.stats = "~edges"),
launchBrowser=F, filename="Kellogg_coauthor_over_time.html",
d3.options = list(slider = TRUE))